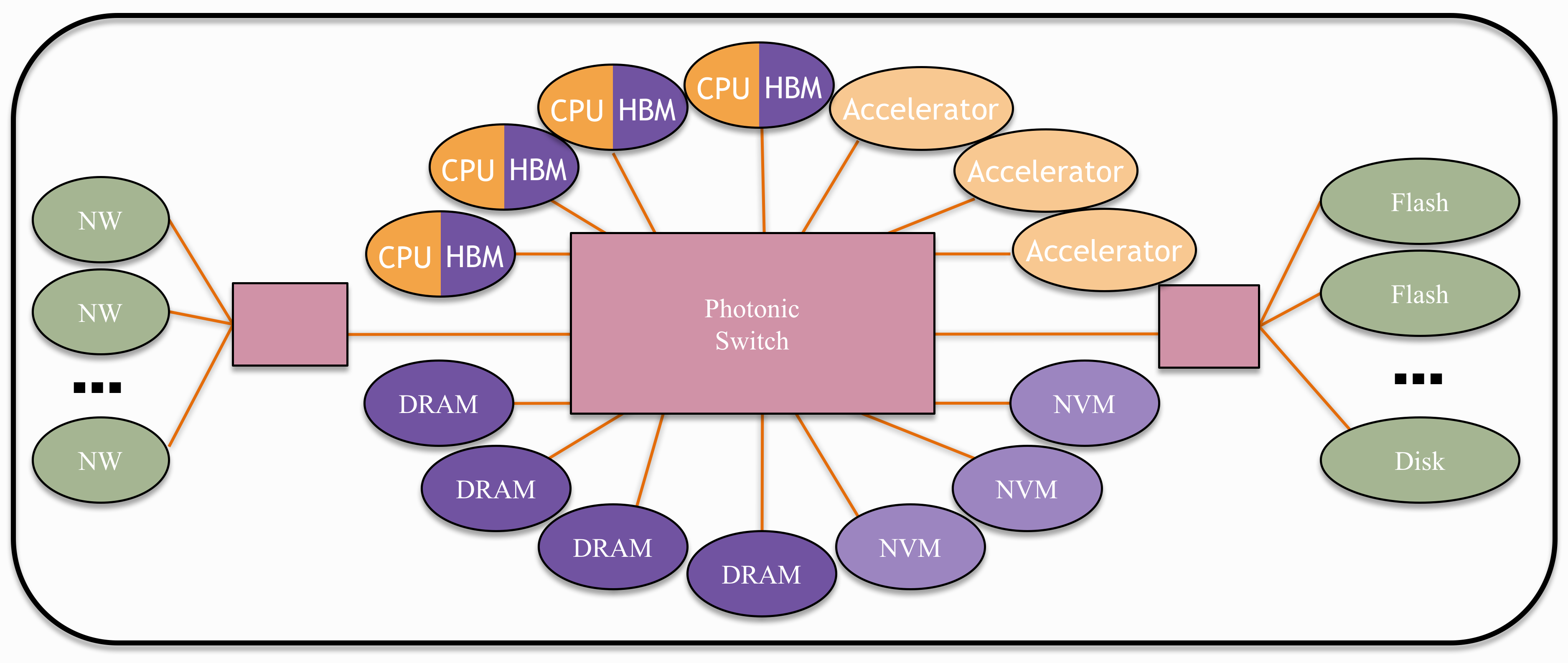
The FireBox project aims to develop a system architecture for third-generation Warehouse-Scale Computers (WSCs). Firebox scales up to a ~1 MegaWatt WSC containing up to 10,000 compute nodes and up to an Exabyte (2^60 Bytes) of non-volatile memory connected via a low-latency, high-bandwidth optical switch. The FireBox project will produce custom datacenter SoCs, distributed simulation tools for warehouse-scale machines, and systems software for FireBox-style disaggregated datacenters.
Background
The complete FireBox design contains petabytes of flash storage, large
quantities of bulk DRAM, as well as high-bandwidth on-package DRAM. Each FireBox
node contains a custom System-on-a-Chip (SoC) with combinations of application
processors, vector machines, and custom hardware accelerators. Fast SoC network
interfaces reduce the software overhead of communicating between application
services and high-radix network backplane switches connected by Terabit/sec
optical fibers reduce the network's contribution to tail latency. The very large
non-volatile store directly supports in-memory databases, and pervasive encryption
ensures that data is always protected in transit and in storage. These system
characteristics raise a number of novel questions in programming environments,
operating systems, and hardware design.
View Krste Asanovic's talk from
FAST'14 below for more details:
The following sections summarize a variety of ongoing FireBox-related projects
in the BAR group.
FireSim is a cycle-accurate FPGA-Accelerated datacenter simulation platform
that uses public-cloud infrastructure to prototype FireBox. See the FireSim project page and
FireSim Website for more information. You can also follow
project updates on Twitter.
FireChip
FireChip is a planned series of tapeouts to prototype FireBox SoCs containing
out-of-order RISC-V cores, accelerators, and high-performance I/O devices.
Bulk Memory Interface
The bulk remote memory in FireBox allows us to scale memory capacity while
allocating it more efficiently between compute nodes. However, the latency (and
possibly bandwidth) will be higher than traditional off-package DRAM. Fast
on-package DRAM allows us to mitigate some of this performance gap, but the
question remains: how best to exploit it?
Swap-Based Interface
One way to harness the on-package DRAM is to use it as a large cache for the
bulk memory. Many operating systems already use virtual memory to treat local
memory as a cache (typically for disk). Previous work at Berkeley has shown that
a swap-based approach may be feasible for some workloads given current
networking technologies (paper here).
Page-Fault Acceleration
Swap-based approaches are able to transparently expose remote memory to
applications, but they introduce non-trivial overheads. In our experiments, a
single page fault can add 1-5us of software overhead. To improve performance
further, one may be tempted to implement a fully hardware-managed DRAM cache.
However, large (multiple GB) hardware caches are complex to implement and don't
have the same insight as the OS. For example, the OS may choose to shrink
I/O caches rather than increase swap traffic, while a HW cache would dutifully
cache useless pages.
To acheive the best of both worlds, we propose a hybrid OS/HW cache. In this
design, hardware manages the latency-critical page fault (cache miss), while the OS handles
the complex eviction logic.
Applications
FireCaffe
Long training times for high-accuracy deep neural networks (DNNs) impede
research into new DNN architectures and slow the development of high-accuracy
DNNs. FireCaffe successfully scales deep neural network training across
a cluster of GPUs.
FireCaffe is designed with FireBox-style warehouse-scale computing in mind.
First, we select network hardware that achieves high bandwidth between GPU
servers. Second, we consider a number of communication algorithms, and we find
that reduction trees are more efficient and scalable than the traditional
parameter server approach. Third, we optionally increase the batch size to
reduce the total quantity of communication during DNN training, and we identify
hyperparameters that allow us to reproduce the small-batch accuracy while
training with large batch sizes.
When training GoogLeNet and Network-in-Network on ImageNet, we achieve a 47x
and 39x speedup, respectively, when training on a cluster of 128 GPUs.